Publications
Group highlights
(For a full list see below or go to Google Scholar)

The growing use of LLMs in search and fact-checking requires improving their accuracy, particularly in querying structured knowledge bases like Wikidata. To address the lack of high-quality training data, we introduce a curated dataset of 2,771 queries designed to fine-tune LLMs for generating accurate SPARQL queries from natural language. Our findings indicate that models perform better on less complex queries, making this dataset a valuable benchmark for text-to-SPARQL evaluation.
Mehdi Ben Amor, Alexis Strappazon, Michael Granitzer, Elöd Egyed-Zsigmond, Jelena Mitrović
We introduce WebFAQ, a large-scale open-domain question-answering dataset containing 96 million QA pairs across 75 languages, with nearly half in non-English languages. WebFAQ serves as a foundation for 20 monolingual retrieval benchmarks and is carefully curated to enhance multilingual dense retrieval models, demonstrating significant performance gains when fine-tuning XLM-RoBERTa. Additionally, we use WebFAQ to construct high-quality bilingual corpora for over 1,000 language pairs, outperforming similar datasets in translation quality.
Michael Dinzinger, Laura Caspari, Kanishka Gosh Dastidar, Jelena Mitrović, Michael Granitzer
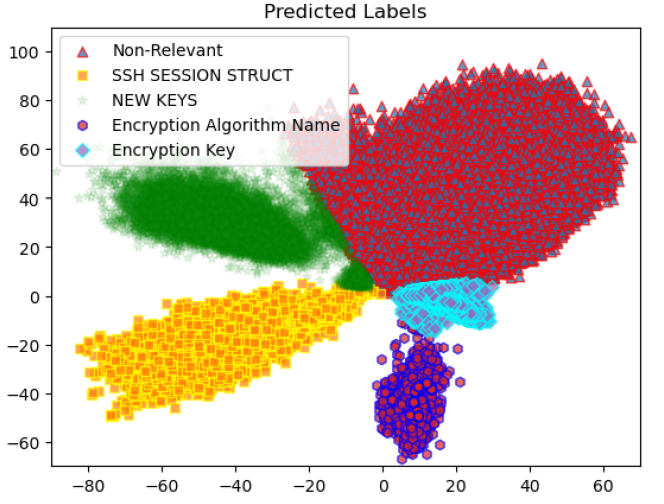
Foundation models have revolutionized NLP and computer vision, but their application in cybersecurity remains largely unexplored. To address this gap, we introduce MemBERT, a foundation model trained on process dump data to enhance memory forensics by identifying intricate memory structures with high efficiency. Our results demonstrate MemBERT’s effectiveness in extracting encryption keys and other memory artifacts while enabling embedding compression with minimal accuracy loss, marking a significant advancement in cybersecurity forensics.
Christofer Fellicious, Mehdi Ben Amor, Johannes Garstenauer, Jelena Mitrović, Hans P. Reiser, Michael Granitzer

Rhetorical figures are used to convey subtle, implicit meaning, or to emphasize statements. By improving the systems for computational detection of rhetorical figures, we can also improve tasks such as hate speech and fake news detection, sentiment analysis, opinion mining, or argument mining. Unfortunately, there is a lack of annotated data, as well as qualified annotators. The situation is particularly difficult in languages other than English. To overcome this issue, we develop a web application called "Find your Figure" that facilitates the identification and annotation of German rhetorical figures. The application is based on the German Rhetorical ontology GRhOOT. In addition, we improve the user experience with Retrieval Augmented Generation (RAG). In this paper, we present the restructuring of the ontology, the development of the web application, and the built-in RAG pipeline. We also identify the optimal RAG settings for our application.
Ramona Kühn, Jelena Mitrović, Michael Granitzer
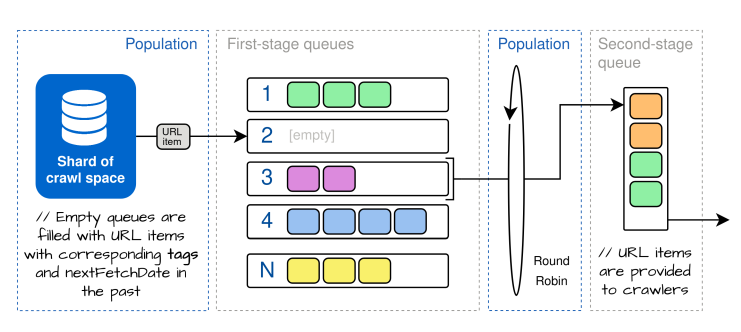
We present the Open Web Crawler (OWLer), an open-source software framework driving the large-scale collection of web documents. OWLer constitutes the backbone of a fully integrated processing pipeline for indexing and sharing large amounts of curated web resources. Technically, OWLer bases on open-source projects such as StormCrawler, OpenSearch and the URLFrontier framework. In this paper, we present the conceptual and technical background, discuss design decisions and overview the architecture of the OWLer crawling system.
Michael Dinzinger, Saber Zerhoudi, Jelena Mitrović, Michael Granitzer
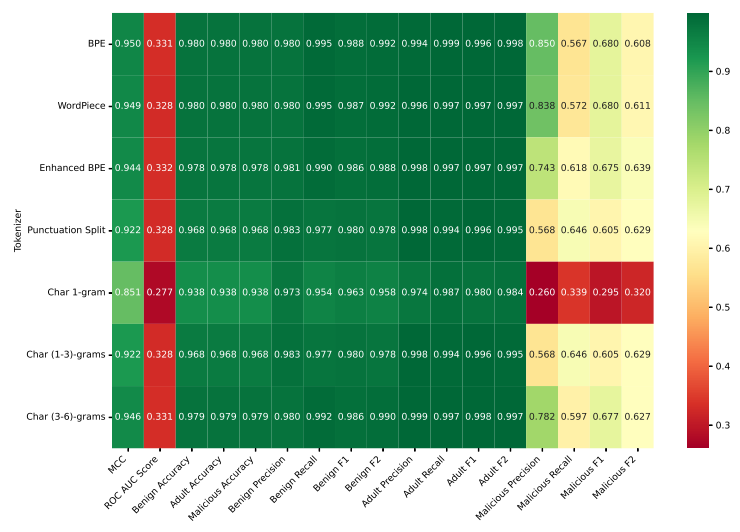
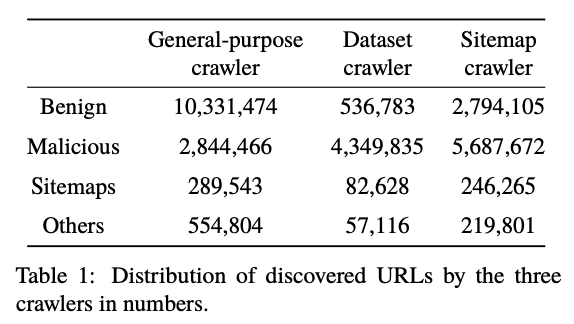
Web crawling can be improved by the accurate classification of URLs to ensure relevant content is indexed and harmful content is filtered out. In this study, we examined the impact of various tokenization techniques on URL classification, a task integral to the development of intelligent web crawlers. Our investigation was conducted using a large-scale dataset of over one million URLs, categorized into 'Malicious', 'Benign', and 'Adult' classes, with detailed sublabels for in-depth analysis.
M. Al-Maamari, M. Istaiti, S. Zerhoudi, M. Dinzinger, M. Granitzer, J. Mitrović
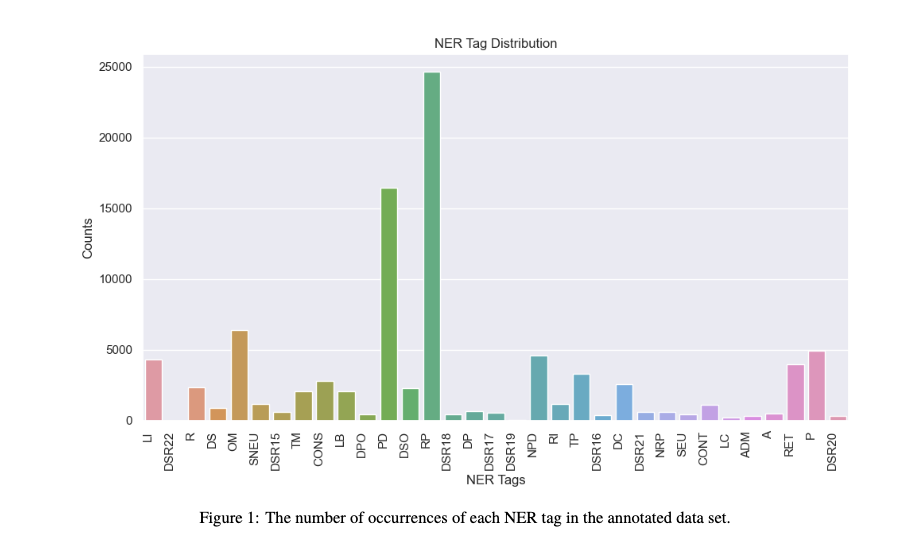
Privacy policies play a vital role in informing users about the data practices of online platforms. They are intended to help them make informed decisions regarding the processing of their personal information. Still, privacy policies are often long and complicated, making it difficult for users to understand how their data is being handled. Natural Language Processing (NLP) techniques, such as Named Entity Recognition (NER), can be employed to automatically extract meaningful information from privacy policies to ease the making of informed decisions. In this work, we present a dataset of privacy policies improved with NER annotations. The dataset consists of privacy policies from 44 online platforms. These policies were annotated to comply with the GDPR guidelines. The privacy policies are manually annotated with NER tags, highlighting relevant entities of GDPR privacy policies such as data controllers, data sources, authority, etc. We also provide the annotation guidelines used by the annotators. This annotated dataset is a valuable resource for training and evaluating NER models in the context of privacy policies.
Harshil Darji, Stefan Becher, Jelena Mitrovic, Armin Gerl, Michael Granitzer
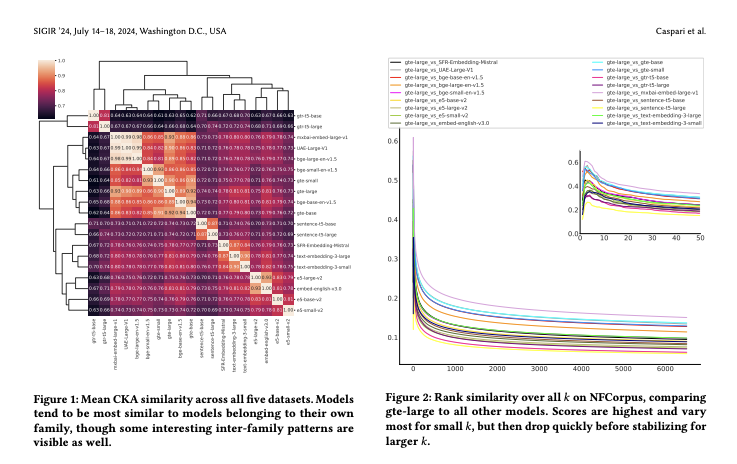
The choice of embedding model is a crucial step in the design of Retrieval Augmented Generation (RAG) systems. Given the sheer volume of available options, identifying clusters of similar models streamlines this model selection process. Relying solely on benchmark performance scores only allows for a weak assessment of model similarity. Thus, in this study, we evaluate the similarity of embedding models within the context of RAG systems. Our assessment is two-fold: We use Centered Kernel Alignment to compare embeddings on a pair-wise level. Additionally, as it is especially pertinent to RAG systems, we evaluate the similarity of retrieval results between these models using Jaccard and rank similarity. We compare different families of embedding models, including proprietary ones, across five datasets from the popular Benchmark Information Retrieval (BEIR). Through our experiments we identify clusters of models corresponding to model families, but interestingly, also some inter-family clusters. Furthermore, our analysis of top-𝑘 retrieval similarity reveals high-variance at low 𝑘 values. We also identify possible open-source alternatives to proprietary models, with Mistral exhibiting the highest similarity to OpenAI models.
Laura Caspari, Kanishka Ghosh Dastidar, Saber Zerhoudi, Jelena Mitrović, Michael Granitzer
Computational detection of rhetorical figures focuses mostly on figures such as metaphor, irony, or sarcasm. However, there exist many more figures that are neither less important nor less prevalent. We want to pinpoint the reasons why researchers often avoid other figures and shed light on the challenges they struggle with when investigating those figures. In this comprehensive survey, we analyzed over 40 papers dealing with the computational detection of rhetorical figures other than metaphor, simile, analogy, sarcasm, and irony. We encountered recurrent challenges from which we compiled a ten-point list. Furthermore, we suggest solutions for each challenge to encourage researchers to investigate a greater variety of rhetorical figures.
Ramona Kühn, Jelena Mitrović
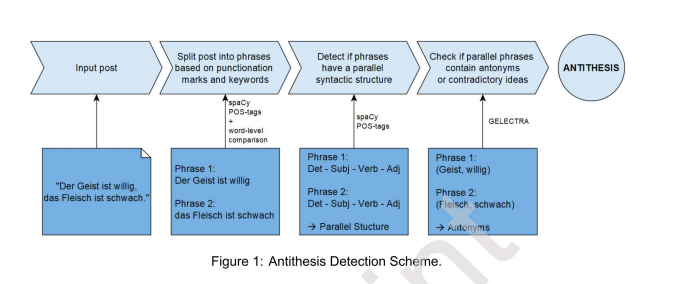
Rhetorical figures play an important role in influencing readers and listeners. Some of these word constructs that deviate from the usual language structure are known to be persuasive - antithesis is one of them. This figure combines parallel phrases with opposite ideas or words to highlight a contradiction. By identifying this figure, persuasive actors can be better identified. For this task, we create an annotated German dataset for antithesis detection. The dataset consists of posts from a Telegram channel criticizing the COVID-19 politics in Germany. Furthermore, we propose a three-block pipeline approach to detect the figure antithesis using large language models. Our pipeline splits the text into phrases, identifies phrases with a syntactically parallel structure, and detects if these parallel phrase pairs present opposing ideas by fine-tuning the German ELECTRA model, a state-of-the-art deep learning model for the German language. Furthermore, we compare the results with multilingual BERT and German BERT. Our novel approach outperforms the state-of-the-art methods (F1 score of 39.70%) for antithesis detection by achieving an F1 score of 65.11%
Ramona Kühn, Khouloud Saadi, Jelena Mitrović and Michael Granitzer
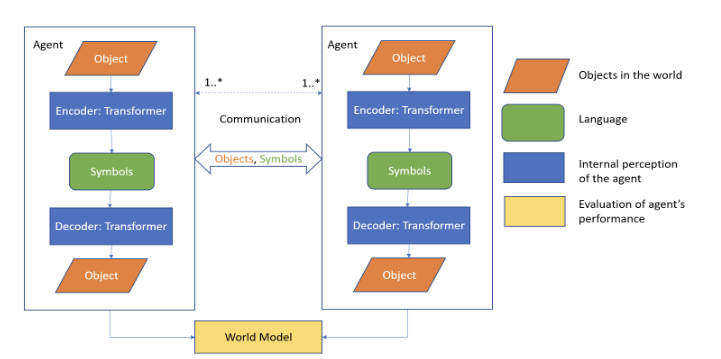
The rise of Large Language Models (LLMs) has increased the relevance of agent-to-agent communication, particularly in systems where agents learn from their interactions. However, current LLMs offer limited insights into the communication dynamics among multiple agents, especially in large-scale settings when multiple agents are involved. Particularly training LLMs - in contrast to in-context learning - becomes nearly infeasible without large-scale computing infrastructure. In our work we present a machine-learning based agent framework to investigate the role of different communication pathways for studying language emergence between machine learning-based agents. We designed a transformer-based image auto-encoder as the agent architecture. A Gumbel SoftMax layer encodes images in form of symbols forming the language between agents. We study two pathways: In the first pathway, the sender reads an image and sends a message to the receiver. The receiver uses the message to reconstruct the sender’s image. In the second pathway, the sender and receiver read an image and minimize the distance between the generated symbols. In the first pathway, language emerges with the Levenshtein distance of ≤ 2 for 96% of messages. In the second pathway, no language emerges with the Levenshtein distance of ≤ 2 for 3% of messages.
Sathish Purushothaman, Michael Granitzer, Florian Lemmerich, Jelena Mitrovic
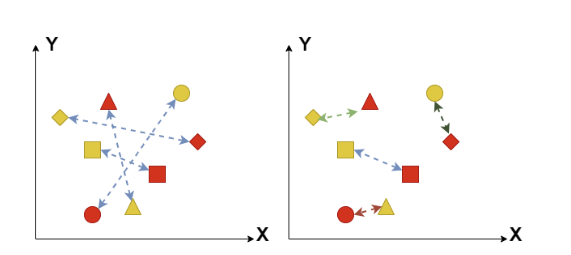
Knowledge Distillation (KD) is an effective technique for compressing large language models through the teacher-student framework. Previous work in feature distillation mainly applied an exact matching between the hidden representations of the student and the teacher. However, as the student has a lower capacity compared to the teacher, it may struggle to mimic its exact hidden representations. This leads to a large discrepancy between their features as shown in preceding research. Therefore, we propose intra-class similarity-guided feature distillation, a novel approach to make the task easier for the student. In this work, we map each sample representation by the student to its K nearest neighbor samples representations by the teacher that are within the same class. This method is novel and can be combined with other distillation techniques. Empirical results show the effectiveness of our proposed approach by maintaining good performance on benchmark datasets.
Khouloud Saadi, Jelena Mitrović and Michael Granitzer
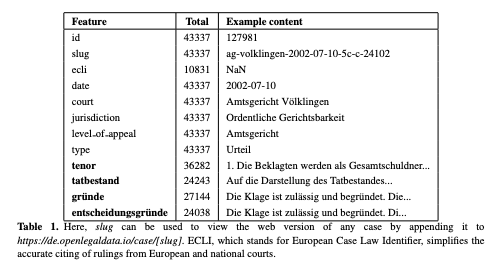
The process of annotating data within the legal sector is filled with distinct challenges that differ from other fields, primarily due to the inherent complexities of legal language and documentation. The initial task usually involves selecting an appropriate raw dataset that captures the intricate aspects of legal texts. Following this, extracting text becomes a complicated task, as legal documents often have complex structures, footnotes, references, and unique terminology. The importance of data cleaning is magnified in this context, ensuring that redundant information is eliminated while maintaining crucial legal details and context. Creating comprehensive yet straightforward annotation guidelines is imperative, as these guidelines serve as the road map for maintaining uniformity and addressing the subtle nuances of legal terminology. Another critical aspect is the involvement of legal professionals in the annotation process. Their expertise is valuable in ensuring that the data not only remains contextually accurate but also adheres to prevailing legal standards and interpretations. This paper provides an expanded view of these challenges and aims to offer a foundational understanding and guidance for researchers and professionals engaged in legal data annotation projects. In addition, we provide links to our created and fine-tuned datasets and language models. These resources are outcomes of our discussed projects and solutions to challenges faced while working on them.
Harshil Darji, Jelena Mitrović and Michael Granitzer
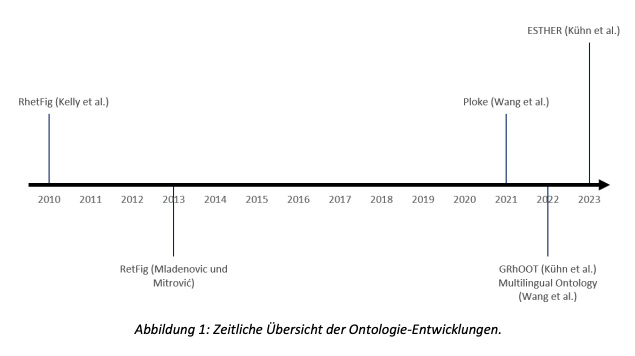
Rhetorische Figuren sind seit Jahrhunderten Gegenstand der Untersuchung in den Bereichen der Linguistik und der Rhetorik. Diese Figuren, wie zum Beispiel Metapher, Ironie, Alliteration und viele weitere, können als Abweichung vom normalen Sprachgebrauch verstanden werden (Fahnestock, 1999). Die daraus resultierende Wirkung ist, dass Texte oder Worte, die rhetorische Figuren enthalten, einprägsamer, überzeugender oder auch beeinflussend sein können. Wir möchten dabei Figuren unterscheiden, die sprachunabhängig funktionieren, wie zum Beispiel die Wiederholung eines Wortes, oder die Verwendung des gleichen Anfangslauts (z. B. bei der Figur Alliteration) und Figuren, die auf einem gemeinsamen kulturellen Verständnis und Hintergrundwissen basieren (z.B. Metaphern wie “jemandem das Herz brechen”) und oft nicht wörtlich, sondern nur im übertragenen Sinne verstanden werden können. Besonders bei Übersetzungen zwischen zwei Sprachen ist es immens wichtig, die Nuancen zu erkennen und richtig zu interpretieren.
Ramona Kühn, Jelena Mitrović
ESTHER, the English ontology of rhetorical figures, is a formal domain ontology of rhetorical figures in the English language. Existing ontologies in this domain mainly focus on figures in other languages, such as Serbian or German. Our ESTHER ontology fills this gap by modeling 85 English rhetorical figures. It aligns with existing ontologies to allow interoperability with other languages. In addition, the ESTHER ontology includes hierarchical relations and compositional features of figures to model their dependency relations. We also provide an overview of current tools and methods of ontological evaluation, validation, and documentation for the ESTHER ontology. Furthermore, we developed a tool to show how the ontology helps annotators without linguistic understanding to annotate instances of rhetorical figures.
Ramona Kühn, Jelena Mitrović and Michael Granitzer
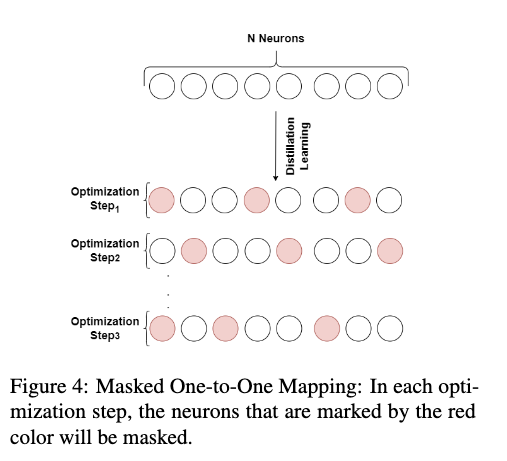
Knowledge distillation is known as an effective technique for compressing over-parameterized language models. In this work, we propose to break down the global feature distillation task into N local sub-tasks. In this new framework, we consider each neuron in the last hidden layer of the teacher network as a specialized subteacher. We also consider each neuron in the last hidden layer of the student network as a focused sub-student. We make each focused sub-student learn from one corresponding specialized sub-teacher and ignore the others. This will facilitate the task for the sub-student and keep it focused. Our proposed method is novel and can be combined with other distillation techniques. Empirical results show that our proposed approach outperforms the state-of-the-art methods by maintaining higher performance on most benchmark datasets. Furthermore, we propose a randomized variant of our approach, called Masked One-to-One Mapping. Rather than learning all the N sub-tasks simultaneously, we focus on learning a subset of these sub-tasks at each optimization step. This variant enables the student to digest the received flow of knowledge more effectively and yields superior results.
Saadi et al.
In the rapidly evolving digital landscape, the need for efficient and effective web crawling mechanisms is more crucial than ever. Web crawlers are instrumental in discovering and indexing new content, and their role in areas such as search engine optimization, data mining, and web archiving is indispensable. However, current distributed crawling frameworks face significant challenges in terms of topic-based content discovery and categorization. This paper presents novel extensions to the StormCrawler and URLFrontier frameworks to enhance web crawling efficiency and relevance. The OWler, a derivative of the StormCrawler, is extended with classification functionalities, including topic identification and thus enabling the production of topic-specific WARC files using multiple writing streams. Concurrently, the URLFrontier framework is extended to enable web crawlers to retrieve URLs based on topic interests. To put it in a nutshell, these extensions allow us to build a highly distributed network of heterogeneous web crawlers, which are nevertheless efficiently collaborating over a shared crawl space.
Dinzinger et al.
While webpage classification may not be a fundamental requirement for basic web crawling, it proves useful in enhancing the prioritization of crawled webpages. In this regard, our study presents a dataset of 116,000 URLs, complete with their content, specifically curated for webpage classification tasks. The primary goal of this research is to establish this comprehensive dataset with two levels of labels for URLs. Firstly, a broad level categorization dividing URLs into Malicious, Benign, or Adult, and secondly, a more nuanced labeling which includes 20 subclasses, providing a more granular view of the webpage content. The secondary objective is to leverage this dataset for testing and comparing the performance of various machine learning models, specifically Stochastic Gradient Descent (SGD) and Support Vector Classifier (SVC), in the task of webpage classification. This involves investigating the effectiveness of different input types (URLs only, raw HTML content, and parsed HTML content) and various tokenization methods (character-level, word-level, Byte Pair Encoding(BPE) [1]) on model performance. A total of 36 experiments were conducted, yielding several important findings. Using only the URL as input consistently resulted in the highest F1 score 0.94. Character-level tokenization consistently outperformed other tokenization techniques. There was a negligible difference in the accuracy of webpage classification between SGD and SVC models. This research’s findings demonstrate the viability of URLbased classification systems in web crawlers and shed light on optimal techniques for feature representation. The comprehensive dataset and results presented in this paper make valuable contributions to the advancement of web crawling applications, especially those requiring effective content prioritization and filtering.
Al-Maamari et al.
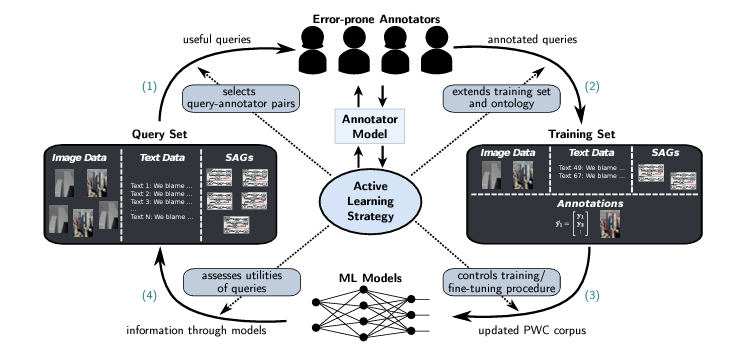
Active learning (AL) techniques hardly cope with complex annotations tasks, where, for example, annotations might express relationships across data modalities. As a use case, we consider the task of automatically detecting and reporting multimodal, polarized web content (PWC). Samples of this content type emerge dynamically, covering a broad spectrum of topics. Thus, training machine learning systems for detecting PWC is challenging, particularly if it needs to be done with minimum annotation cost. In this article, we propose the concept of multimodal AL for complex annotations in the context of PWC detection and formulate the resulting challenges as questions for future research.
Herde, Marek and Huseljic, Denis and Mitrovic, Jelena and Granitzer, Michael and Sick, Bernhard
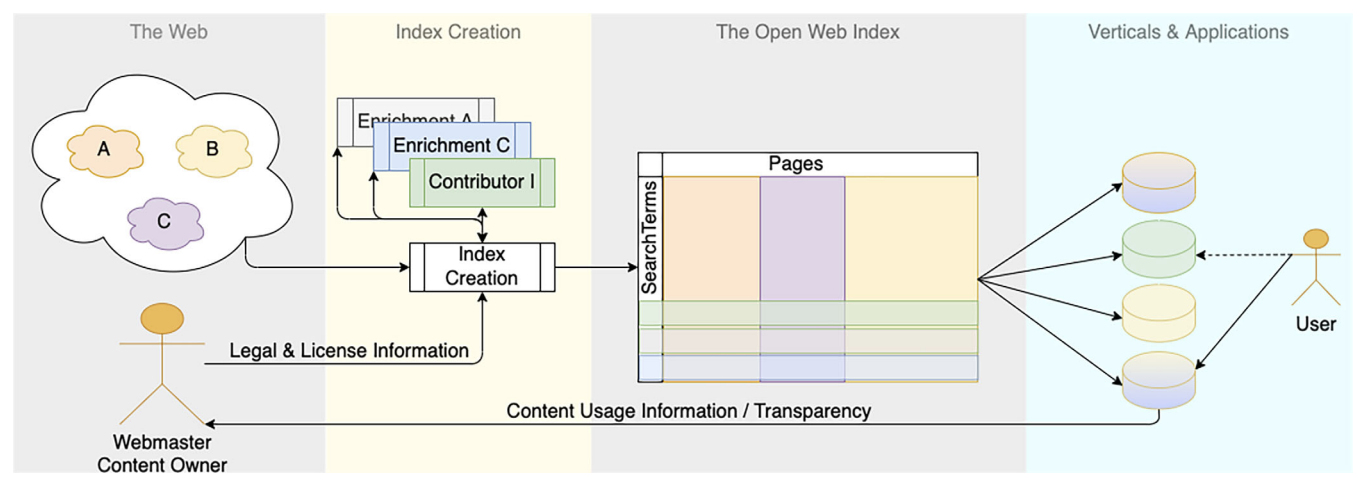
Web search is a crucial technology for the digital economy. Dominated by a few gatekeepers focused on commercial success, however, web publishers have to optimize their content for these gatekeepers, resulting in a closed ecosystem of search engines as well as the risk of publishers sacrificing quality. To encourage an open search ecosystem and offer users genuine choice among alternative search engines, we propose the development of an Open Web Index (OWI). We outline six core principles for developing and maintaining an open index, based on open data principles, legal compliance, and collaborative technology development. The combination of an open index with what we call declarative search engines will facilitate the development of vertical search engines and innovative web data products (including, e.g., large language models), enabling a fair and open information space. This framework underpins the EU-funded project OpenWebSearch.EU, marking the first step towards realizing an Open Web Index.
Granitzer et al.
In this study, we discuss the challenges of understanding and detecting rhetorical figures in natural language processing (NLP) tasks. We propose the creation of formal domain ontologies of rhetorical figures in different languages to assist in the annotation process and improve NLP tasks such as machine translation, hate speech detection, text summarization, and sentiment analysis. We present and compare existing ontologies in the domain of rhetorical figures, identify their properties, and demonstrate how they can be used for various NLP tasks. We also emphasize the need to promote the creation of ontologies of rhetorical figures in other languages to decrease inequalities in NLP research.
Ramona Kühn, Jelena Mitrović
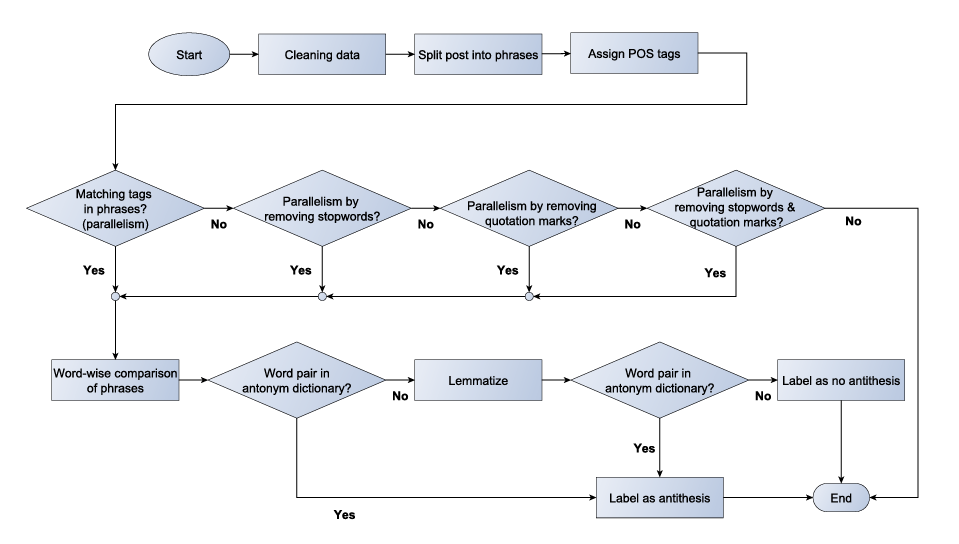
Existing wordnets mainly focus on synonyms, while antonyms have often been neglected, especially in wordnets in languages other than English. In this paper, we show how regular expressions are used to generate an antonym resource for German by using Wiktionary as a source. This resource contains antonyms for 45499 words. The antonyms can be used to extend existing wordnets. We show that this is important by comparing our antonym resource to the antonyms in OdeNet, the only freely available German wordnet that contains antonyms for 3059 words. We demonstrate that antonyms are relevant for the detection of the rhetorical figure antithesis. This figure has been known to influence the audience by creating contradiction and using a parallel sentence structure combined with antonyms. We first detect parallelism with part-of-speech tags and then apply our rule-based antithesis detection algorithm to a dataset of the messenger service Telegram. We evaluate our approach and achieve a precision of 57% and are call of 45% thus overcoming the existing approaches.
Ramona Kühn, Jelena Mitrović and Michael Granitzer
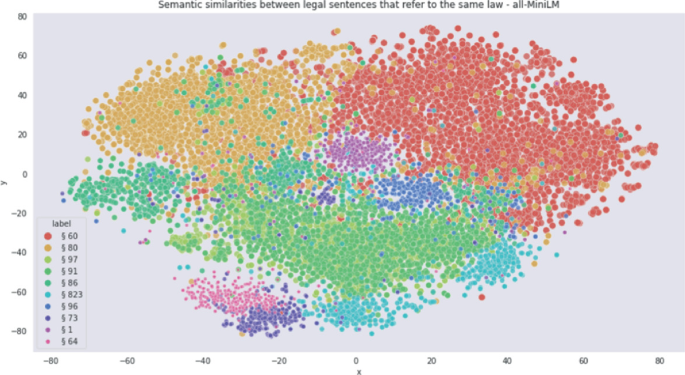
The calculation of semantic similarity is an important task in Natural Language Processing (NLP). There is a growing interest in this task in the research community, especially following the advent of new, ever-evolving neural architectures. However, this technique has not been explored in-depth in the realm of automatic processing of legal data, the area we often call Legal NLP or Legal Tech. In this paper, we aim to use semantic similarity to identify the relations between legal sentences that refer to a certain law and the law text itself. The semantic similarity score is calculated using cosine similarity between sentence embeddings. In our work, we use sentence transformers to get the sentence embeddings for our legal text. The results we achieve by using two separate sentence transformers, Cross English & German RoBERTa and all-MiniLM-L6-v2, provide a semantic similarity score of approximately 0.45 and 0.4, respectively.
Harshil Darji, Jelena Mitrović and Michael Granitzer
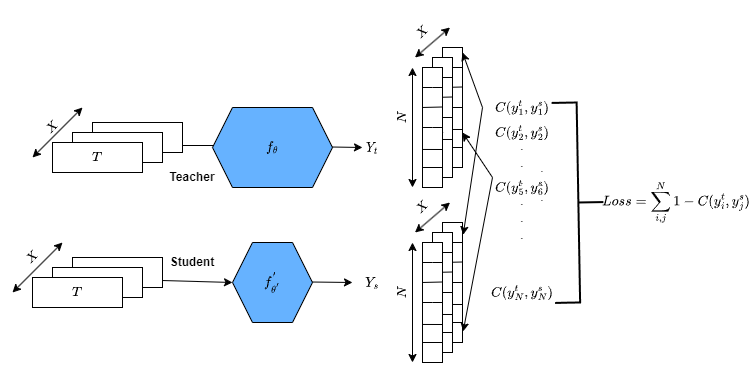
Knowledge Distillation is known as an effective technique to compress over-parameterized language models. In this work, we propose to break down the global feature distillation task into N local sub-tasks. In this new framework, we consider each neuron in the last hidden layer of the teacher network as a specialized sub-teacher. We also consider each neuron in the last hidden layer of the student network as a focused sub-student. We make each focused sub-student learn from one corresponding specialized sub-teacher and ignore the others. This will facilitate the task for the sub-student and keep him focused. This method is novel and can be combined with other distillation techniques. Empirical results show that our pro- posed approach outperforms the state-of-the-art methods by maintaining higher performance on most benchmark datasets.
Khouloud Saadi, Jelena Mitrović and Michael Granitzer
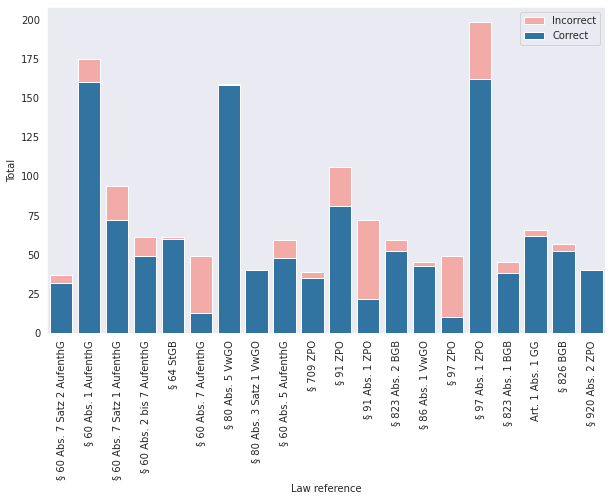
The field of legal Natural Language Processing faces a lot of challenges due to the unavailability of properly structured datasets. One such instance is the need for a dataset that not only separates different parts of legal references, such as an article or paragraph number but also provides information about what a particular legal reference dictates. Having access to such a dataset can provide easy access to researchers working on experiments such as context similarity between law texts and legal cases that refer to a particular law.
Harshil Darji, Jelena Mitrović and Michael Granitzer
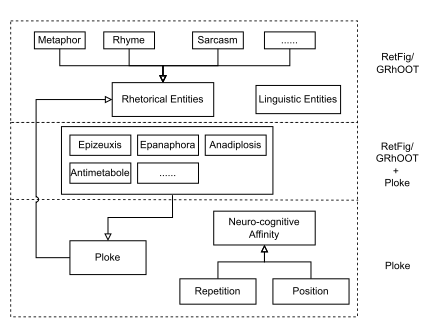
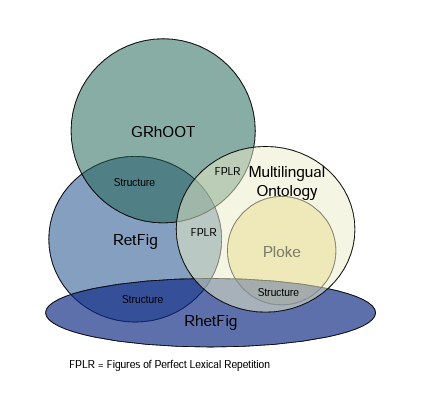
This paper focuses on figures of perfect lexical repetition and their representation in three ontologies in three different languages: The Ploke ontology, the Serbian RetFig, and the German GRhOOT ontology. We combine those ontologies to benefit from synergy effects and create a multilingual, coherent, robust, and modular ontology for rhetorical figures of perfect lexical repetition.
Yetian Wang, Ramona Kühn, Randy Allen Harris, Jelena Mitrović, and Michael Granitzer
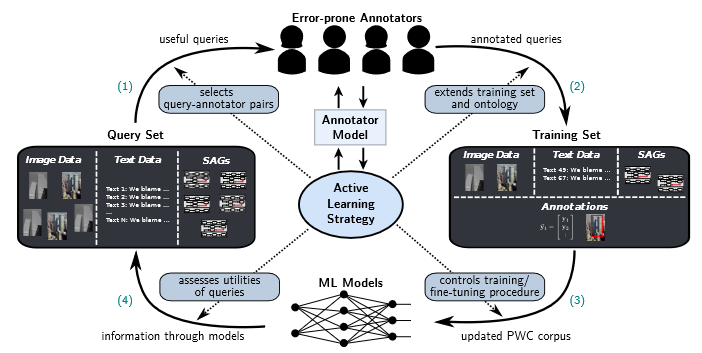
Active learning techniques hardly cope with complex annotations tasks, where annotations might express relationships across data modalities. As a use case, we consider the task of automatically detecting and reporting multimodal, polarized web content. We propose the concept of multimodal AL for complex annotations in the context of PWC detection.
Marek Herde, Denis Huseljic, Jelena Mitrović, Michael Granitzer, and Bernhard Sick
A Concept for Automated Polarized Web Content Annotation based on Multimodal Active Learning
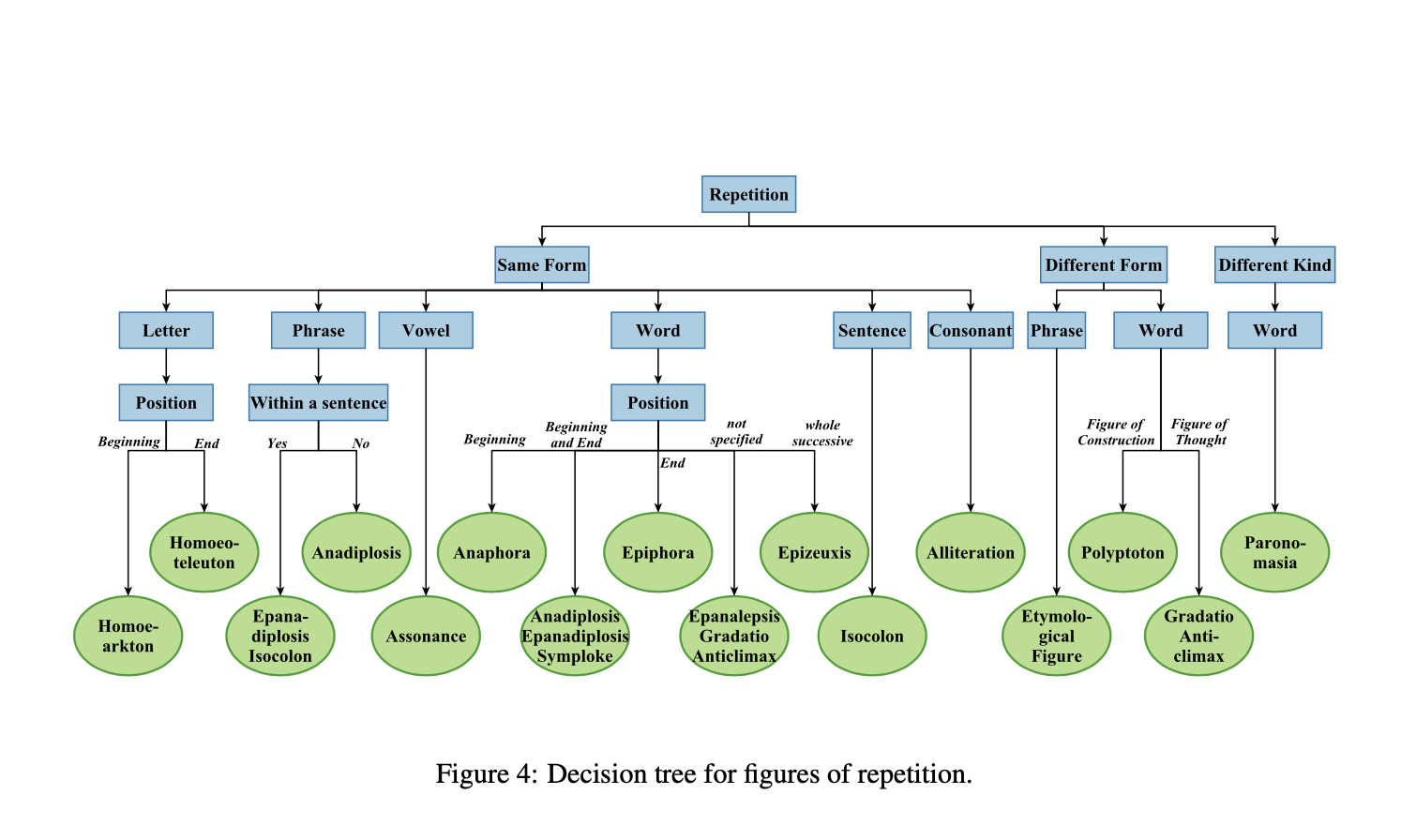
GRhOOT, the German RhetOrical OnTology, is a domain ontology of 110 rhetorical figures in the German language. The overall goal of building an ontology of rhetorical figures in German is not only the formal representation of different rhetorical figures, but also allowing for their easier detection, thus improving sentiment analysis, argument mining, detection of hate speech and fake news, machine translation, and many other tasks in which recognition of non-literal language plays an important role.
Ramona Kühn, Jelena Mitrović and Michael Granitzer
GRhOOT, the German RhetOrical OnTology
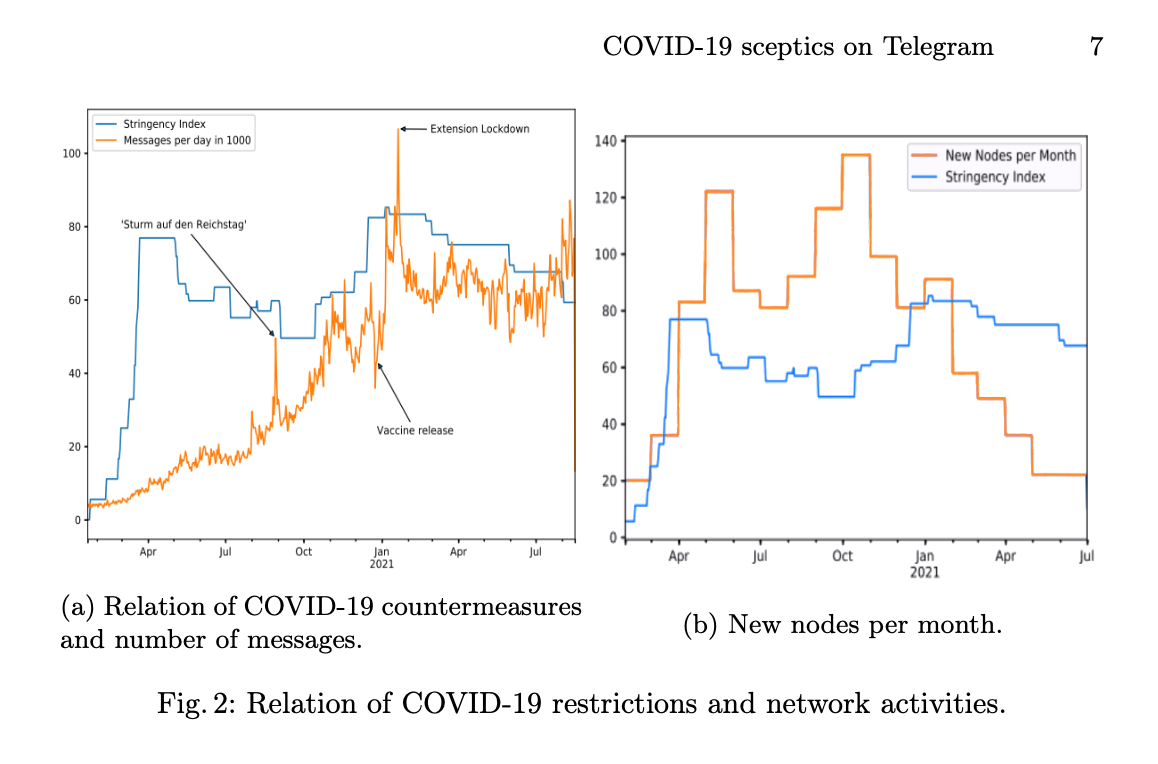
We present an effective way to create a dataset from relevant channels and groups of the messenger service Telegram, to detect clus- ters in this network, and to find influential actors. Our focus lies on the network of German COVID-19 sceptics that formed on Telegram along with growing restrictions meant to prevent the spreading of COVID-19.
Valentin Peter, Ramona Kühn, Jelena Mitrović, Michael Granitzer and Hannah Schmid-Petri
Network Analysis of German COVID-19 Related Discussions on Telegram
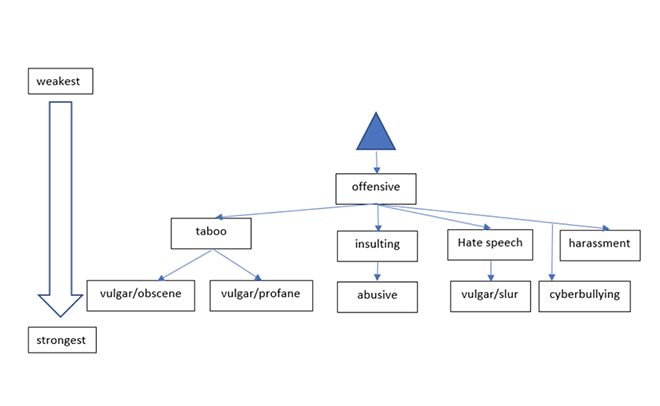
The main focus of the paper is the definitional revision and enrichment of offensive language typology, making reference to publicly available offensive language datasets and testing them on available pretrained lexical embedding systems. We review over 60 available corpora and compare tagging schemas applied there while making an attempt to explain semantic differences between particular concepts of the category OFFENSIVE in English.
Barbara Lewandowska-Tomaszczyk, Slavko Žitnik, Anna Bączkowska, Chaya Liebeskind, Jelena Mitrović and Giedre Valunaite Oleskeviciene
A finite set of classes that cover aspects of offensive language representation

This paper examines several widespread assumptions about artificial intelligence, particularly machine learning, that are often taken as factual premises in discussions on the future of patent law in the wake of ‘artificial ingenuity’. The objective is to draw a more realistic and nuanced picture of the human-computer interaction in solving technical problems than where ‘intelligent’ systems autonomously yield inventions. A detailed technical perspective is presented for each assumption, followed by a discussion of pertinent uncertainties for patent law. Overall, it is argued that implications of machine learning for the patent system in its core tenets appear far less revolutionary than is often posited.
Daria Kim, Maximilian Alber, Man Wai Kwok, Jelena Mitrović, Cristian Ramirez-Atencia, JesÚs Alberto RodrÍguez Pérez, Heiner Zille
The paper examines several widespread assumptions about artificial intelligence
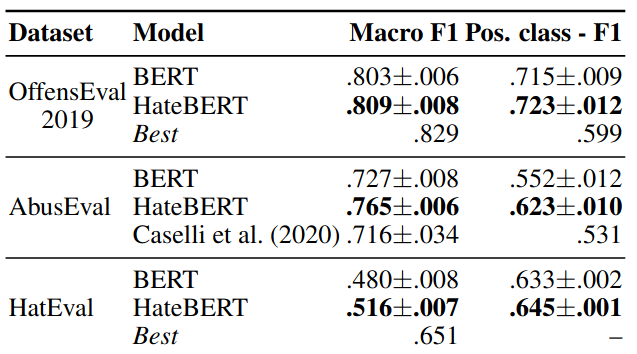
We introduce HateBERT, a re-trained BERT model for abusive language detection inEnglish. The model was trained on RAL-E, a large-scale dataset of Reddit comments in Englishfrom communities banned for being offensive, abusive, or hateful that we have collected andmade available to the public. Results and trained models are published on an OSF repository.
Caselli Tommaso, Basile Valerio, Jelena Mitrović and Michael Granitzer
Proceedings of the 5th Workshop on Online Abuse and Harms (WOAH) ACL-IJCNPL 2021 2021
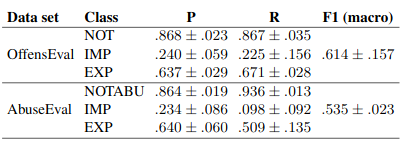
In this contribution, we investigate a recent dataset for offensive language in English, namely OLID/OffensEval (Zampieri et al. 2019a; Zampieri et al. 2019b), in the light of two factors proposed by Waseem et al. 2017.
Tommaso Caselli, Valerio Basile, Jelena Mitrovic, Inga Kartoziya, Michael Granitzer
12th Conference on Language Resources and Evaluation (2020)

We discuss ontological modeling of legal terminology in formal ontologies, such is SUMO (Pease, 2001) and the possibility of utilizing its close connection to the lexical-semantic network WordNet (Fellbaum, 1998) in the legal domain. Formal systems that allow for automated semantic interpretation of law supported by lexical resources can bring forth solutions to legal reasoning tasks.
Jelena Mitrović, Adam Pease, Michael Granitzer
TOTh 2019, Terminology and Ontology; Theories and applications
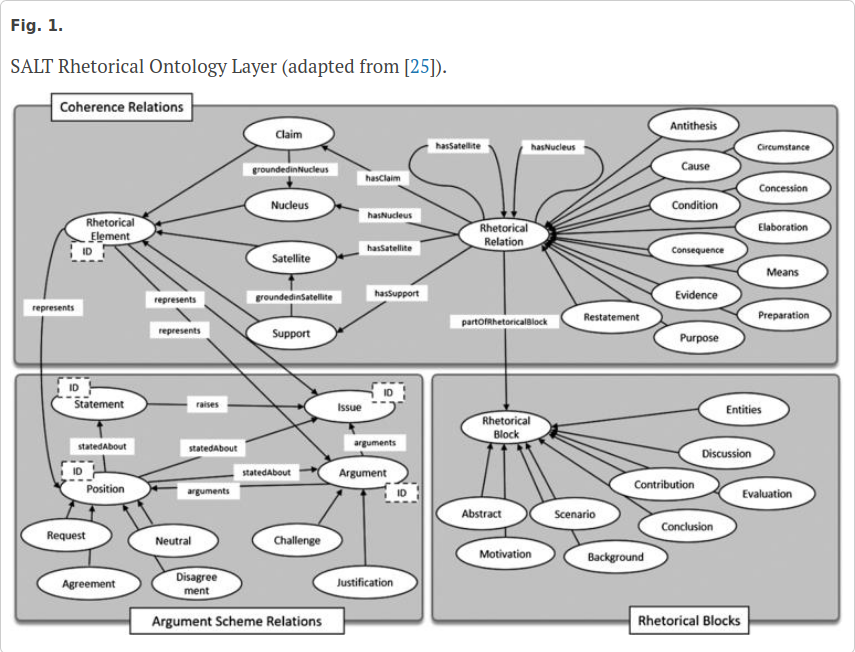
This paper surveys ontological modeling of rhetorical concepts, developed for use in argument mining and other applications of computational rhetoric, projecting their future directions. We include ontological models of argument schemes applying Rhetorical Structure Theory (RST); the RhetFig proposal for modeling; the related RetFig Ontology of Rhetorical Figures for Serbian (developed by two of the authors); and the Lassoing Rhetoric project (developed by another of the authors).
Jelena Mitrović, Cliff O’Reilly, Miljana Mladenović and Siegfried Handschuh
Argument & Computation, vol. 8, no. 3, pp. 267-287, 2017
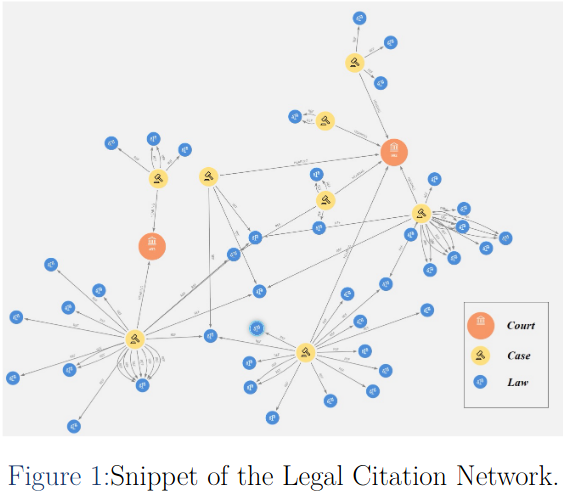
The paper introduces the creation and analysis of a German legal citation network. The network consists of over 200.000 German court cases from all levels of appeal and jurisdiction and more than 50.000 laws. References to court decisions and laws are extracted from within the decision text of the court cases and added as links to the network. We apply network-based analysis techniques to support common legal information retrieval tasks such as identification of important court decisions and laws and case similarity searches. Furthermore, we demonstrate that the German case citation network displays scale-free behaviour, similar to that of the U.S. and Austrian Supreme Courts as shown by previous research.
Tobias Milz, Michael Granitzer, Jelena Mitrović
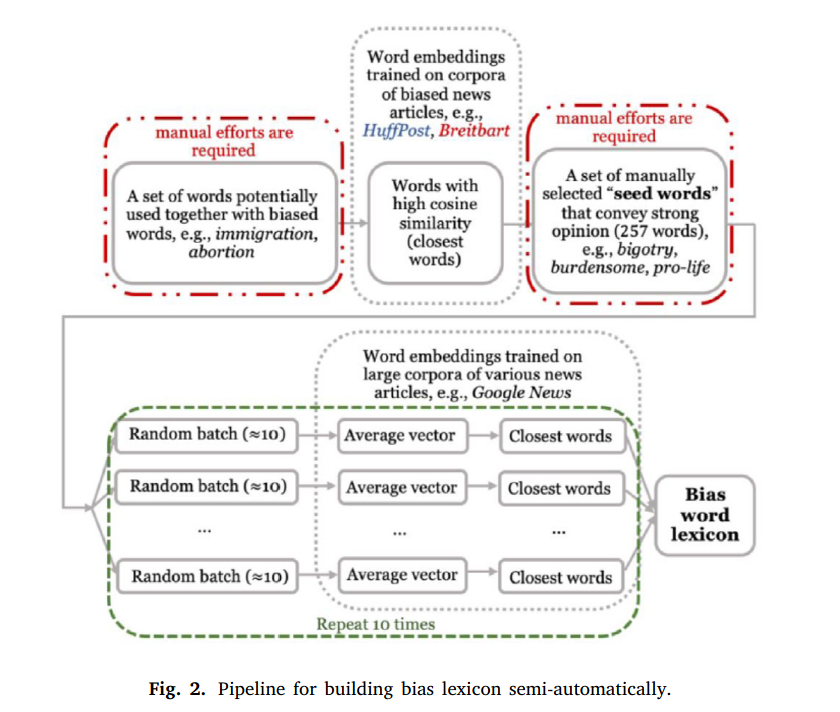
We present a prototypical yet robust anddiverse data set for media bias research. It consists of 1,700 statements representing variousmedia bias instances and contains labels for media bias identification on the word and sentencelevel. In contrast to existing research, our data incorporate background information on theparticipants’ demographics, political ideology, and their opinion about media in general.
Timo Spinde, Lada Rudnitckaia, Jelena Mitrović, Felix Hamborg, Michael Granitzer, Bela Gipp, Karsten Donnay
Information Processing & Management 2021
Artificial Intelligence (AI) and Machine Learning (ML) are becoming an increasingly important part of today's businesses. Web search, spam filters and ads recommendation systems rely heavily on AI and ML. However, this "AI Industry" is currently mainly located in Silicon Valley, which creates an imbalanced situation in the research community: while funding, computational resources, and data are all plentiful and available for the researchers located in US and Canada, the situation in Europe is less stellar.
Jelena Mitrović, Tomáš Mikolov, and Michael Granitzer
Open Web Search for AI and NLP in Europe
Full List
-
Analysis of a German Legal Citation Network2021
-
A Stacking Approach for Cross-Domain Argument IdentificationThe 32nd International Conference on Database and Expert Systems Applications DEXA 2021 2021
-
DistilBERT-based Argumentation Retrieval for Answering Comparative QuestionsConference and Labs of the Evaluation Forum CLEF 2021 2021
-
Hatebert: Retraining bert for abusive language detection in englishProceedings of the 5th Workshop on Online Abuse and Harms (WOAH) ACL-IJCNPL 2021 2021
-
Automated identification of bias inducing words in news articles using linguistic and context-oriented featuresInformation Processing & Management 2021
-
Design and Implementation of German Legal Decision CorporaIn Proceedings of the 13th International Conference on Agents and Artificial Intelligence 2021
-
Language Proficiency ScoringIn Proceedings of the 12th Language Resources and Evaluation Conference 2020
-
Cognitive Modeling in Computational Rhetoric: Litotes, Containment and the Unexcluded Middle.In ICAART (2) 2020
-
Grupato at semeval-2020 task 12: Retraining mbert on social media and fine-tuned offensive language modelsIn Proceedings of the Fourteenth Workshop on Semantic Evaluation 2020
-
Heterogeneous photocatalytic degradation of anthraquinone dye Reactive Blue 19: optimization, comparison between processes and identification of intermediate productsWater SA 2020
-
NLP_Passau at SemEval-2020 Task 12: Multilingual Neural Network for Offensive Language Detection in English, Danish and TurkishIn Proceedings of the Fourteenth Workshop on Semantic Evaluation 2020
-
Towards Classifying Parts of German Legal Writing Styles in German Legal JudgmentsIn 2020 10th International Conference on Advanced Computer Information Technologies (ACIT) 2020
-
Multi-word Expressions for Abusive Speech Detection in SerbianIn Proceedings of the Joint Workshop on Multiword Expressions and Electronic Lexicons 2020
-
Language Proficiency ScoringIn Proceedings of The 12th Language Resources and Evaluation Conference 2020
-
nlpUP at SemEval-2020 Task 12: A Blazing Fast System for Offensive Language DetectionIn Proceedings of the Fourteenth Workshop on Semantic Evaluation 2020
-
I feel offended, don’t be abusive! implicit/explicit messages in offensive and abusive languageIn Proceedings of The 12th Language Resources and Evaluation Conference 2020
-
Modeling Legal Terminology in SUMOProceedings of TOTh 2019
-
nlpUP at SemEval-2019 task 6: A deep neural language model for offensive language detectionIn Proceedings of the 13th International Workshop on Semantic Evaluation 2019
-
upInf-Offensive Language Detection in German TweetsIn Proceedings of the GermEval 2018 Workshop 2018
-
Using lexical resources for irony and sarcasm classificationIn Proceedings of the 8th Balkan Conference in Informatics 2017
-
Ontological representations of rhetorical figures for argument miningArgument & Computation 2017
-
Hybrid sentiment analysis framework for a morphologically rich languageJournal of Intelligent Information Systems 2016
